그렇다면 1000만개 학습한 것을 미세조정 해보는것이 어떠한가?
Eff1의 구조를 한번 알아보자.
https://hoya012.github.io/blog/EfficientNet-review/

EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 리뷰
ICML 2019에 제출된 “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” 논문에 대한 리뷰를 수행하였습니다.
hoya012.github.io

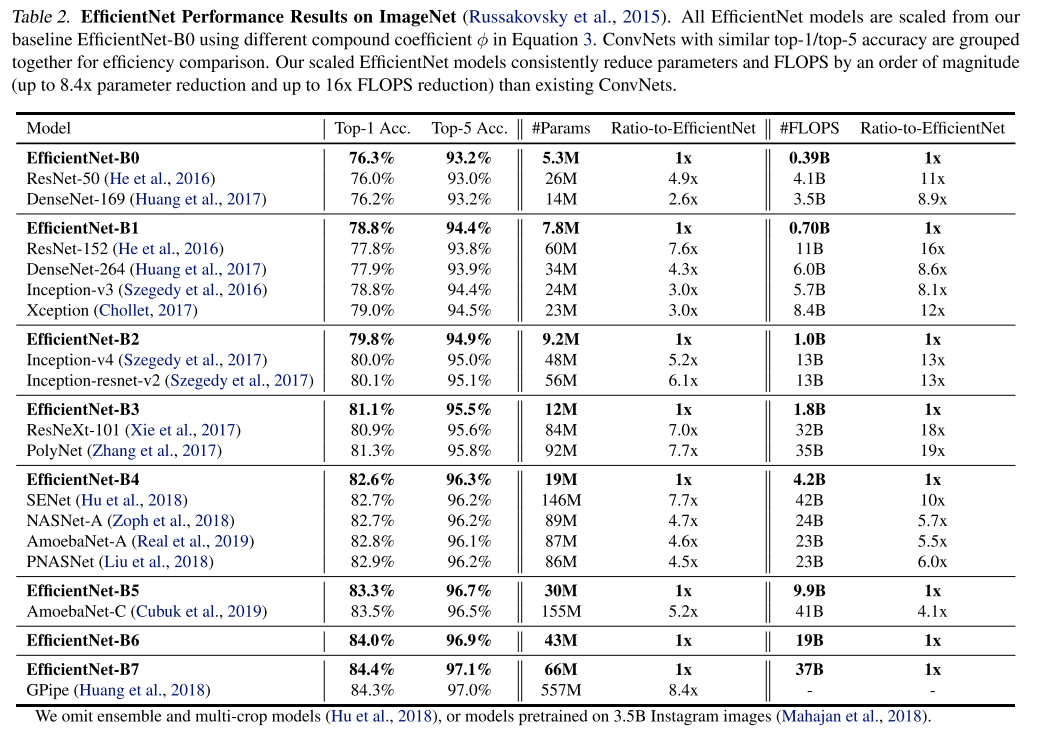
https://keras.io/examples/vision/image_classification_efficientnet_fine_tuning/
Keras documentation: Image classification via fine-tuning with EfficientNet
Image classification via fine-tuning with EfficientNet Author: Yixing Fu Date created: 2020/06/30 Last modified: 2020/07/16 Description: Use EfficientNet with weights pre-trained on imagenet for Stanford Dogs classification. View in Colab • GitHub source
keras.io
Tips for fine tuning EfficientNet
On unfreezing layers:
- The BathcNormalization layers need to be kept frozen (more details). If they are also turned to trainable, the first epoch after unfreezing will significantly reduce accuracy.
- In some cases it may be beneficial to open up only a portion of layers instead of unfreezing all. This will make fine tuning much faster when going to larger models like B7.
- Each block needs to be all turned on or off. This is because the architecture includes a shortcut from the first layer to the last layer for each block. Not respecting blocks also significantly harms the final performance.
Some other tips for utilizing EfficientNet:
- Larger variants of EfficientNet do not guarantee improved performance, especially for tasks with less data or fewer classes. In such a case, the larger variant of EfficientNet chosen, the harder it is to tune hyperparameters.
- EMA (Exponential Moving Average) is very helpful in training EfficientNet from scratch, but not so much for transfer learning.
- Do not use the RMSprop setup as in the original paper for transfer learning. The momentum and learning rate are too high for transfer learning. It will easily corrupt the pretrained weight and blow up the loss. A quick check is to see if loss (as categorical cross entropy) is getting significantly larger than log(NUM_CLASSES) after the same epoch. If so, the initial learning rate/momentum is too high.
- Smaller batch size benefit validation accuracy, possibly due to effectively providing regularization.
어디서부터 fine-tuning을 할 것이냐?
def unfreeze_model(model):
# We unfreeze the top 20 layers while leaving BatchNorm layers frozen
for layer in model.layers[-20:]:
if not isinstance(layer, layers.BatchNormalization):
layer.trainable = True
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(
optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]
)
unfreeze_model(model)모델을 build한 이후에 가중치를 불러오고
그다음에 unfreeze_model함수를 사용해서 layers를 unfreeze해야한다.
def unfreeze_encoder(encoder):
for layer in encoder.layers[0].layers[-31:]:
if not isinstance(layer, tf.keras.layers.BatchNormalization):
layer.trainable = True



미세 조정이 잘 될지 모르겠다. .. 잘 안되는것 같다. 왜일까?

이렇게 해야하네
Resnet은 파라미터의 개수가 너무 많아서 학습이 오래걸릴 것 같고..60,192,808개..
effb0는 파라미터의 개수가 약 720만개정도밖에 안된다.
encoder unfreeze시도
1. 기존 1000만개 데이터 학습한 것 val_loss : 0.1078
- a. 모든 layer를 unfreeze : kaggle tpu로 학습중.. train loss, val_loss가 점점 떨어지고 있음..
- b. 7번째 블록? 상위 31개layer만 unfreeze : colab tpu로 학습중.. val_loss가 0.1077로 떨어지긴 했지만 거의 그대로라고 보면 됨
2. 9300만개 데이터를 학습시키는데 초기학습부터 인코더의 effb0의 layers를 모두 unfreeze해서 kaggle-tpu로 학습중

생각보다 학습이 굉장히 잘 진행되고 있음.
학습이 굉장히 잘 되어서..
val_loss 0.005에서 public score : 0.97569
val_loss가 0.0038까지 떨어짐 public score :
현재 lr=0.0001로 학습중.
어떻게 해야 0.99를 찍을 수 있을까?? 단일모델으론 불가능한가? 앙상블을 해야하나..
계속 학습중..
이제 어떤 방향으로 나아가야하나. 계속 학습 Or 앙상블?
하위 절반에 포함된 문자를 가진 smiles도(만) 학습시켜서(약 1억천만-9300만)앙상블해보자?