 [데이터마이닝] 5.링크분석(Link analysis) 5.5절 연습문제(Exercise 5.5)
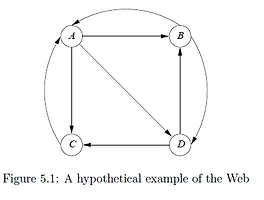
Exercise 5.5.1 : Compute the hubbiness and authority of each of the nodes in our original Web graph of Fig. 5.1. n = 4 sqrt(n) a = c(1/2,1/2,1/2,1/2) h = c(1/2,1/2,1/2,1/2) A = matrix(c(0,1,1,1, 1,0,0,1, 1,0,0,0, 0,1,1,0), nrow = 4) h = A%*%a h = h/max(h) a = t(A)%*%h a = a/max(a) pre_h =0 pre_a =0 while(pre_h != h || pre_a != a){ pre_h = h h = A%*%a h = h/max(h) pre_a = a a = t(A)%*%h a = a/max..
[데이터마이닝] 5.링크분석(Link analysis) 5.5절 연습문제(Exercise 5.5)
Exercise 5.5.1 : Compute the hubbiness and authority of each of the nodes in our original Web graph of Fig. 5.1. n = 4 sqrt(n) a = c(1/2,1/2,1/2,1/2) h = c(1/2,1/2,1/2,1/2) A = matrix(c(0,1,1,1, 1,0,0,1, 1,0,0,0, 0,1,1,0), nrow = 4) h = A%*%a h = h/max(h) a = t(A)%*%h a = a/max(a) pre_h =0 pre_a =0 while(pre_h != h || pre_a != a){ pre_h = h h = A%*%a h = h/max(h) pre_a = a a = t(A)%*%h a = a/max..
 [데이터마이닝] 5.링크분석(Link analysis) 5.3절 연습문제(Exercise 5.3.5 )
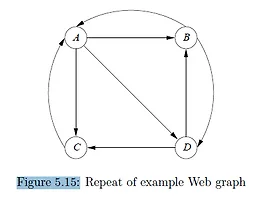
Exercise 5.3.1 : Compute the topic-sensitive PageRank for the graph of Fig. 5.15, assuming the teleport set is: (a) A only. M = matrix(c(0, 1/3 ,1/3 ,1/3, 1/2,0,0,1/2, 1,0,0,0, 0, 1/2 , 1/2, 0),nrow = 4) r = matrix(c(1/4,1/4,1/4,1/4)) beta = 0.8 es = matrix(c(1,0,0,0),nrow=4) s = 1 pre_r = r r = (beta*M)%*%r + (1-beta)/s * es while(pre_r != r ){ pre_r = r r = (beta*M)%*%r + (1-beta)/s * es } r (..
[데이터마이닝] 5.링크분석(Link analysis) 5.3절 연습문제(Exercise 5.3.5 )
Exercise 5.3.1 : Compute the topic-sensitive PageRank for the graph of Fig. 5.15, assuming the teleport set is: (a) A only. M = matrix(c(0, 1/3 ,1/3 ,1/3, 1/2,0,0,1/2, 1,0,0,0, 0, 1/2 , 1/2, 0),nrow = 4) r = matrix(c(1/4,1/4,1/4,1/4)) beta = 0.8 es = matrix(c(1,0,0,0),nrow=4) s = 1 pre_r = r r = (beta*M)%*%r + (1-beta)/s * es while(pre_r != r ){ pre_r = r r = (beta*M)%*%r + (1-beta)/s * es } r (..







