 [I2S]B3을 이용한 결과.
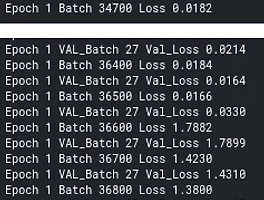
300*300사이즈를 그대로 이용하기위해 effb3를 이용했는데 gradient exploding이 일어났다. 왜인가? 따시 한번 lr=0.0001로 놓고 학습하였더니 굉장히 안정적으로 학습이 되고 있다. 계속 학습을 시켜보도록 하자 val_loss는 0.0150 0.0028이하가 되어야 B0보다 좋다고 할수 있는데 그렇지 않다. 이유가 무엇일까? 1. 너무 많은 파라미터. b3 : 10,696,232, feature map의 크기가 너무 큼 (None, 10,10,1536) b0 : 4,049,564(None,7,7,1280) 이를 해결하기 위해선 decoder를 더 깊게 만들어야할듯. 이정도 파라미터정도는 되어야 ㅎ --> 메모리가 부족해서 batch_size를 32*8로 줄여야한다. b3을 이용하기..
[I2S]B3을 이용한 결과.
300*300사이즈를 그대로 이용하기위해 effb3를 이용했는데 gradient exploding이 일어났다. 왜인가? 따시 한번 lr=0.0001로 놓고 학습하였더니 굉장히 안정적으로 학습이 되고 있다. 계속 학습을 시켜보도록 하자 val_loss는 0.0150 0.0028이하가 되어야 B0보다 좋다고 할수 있는데 그렇지 않다. 이유가 무엇일까? 1. 너무 많은 파라미터. b3 : 10,696,232, feature map의 크기가 너무 큼 (None, 10,10,1536) b0 : 4,049,564(None,7,7,1280) 이를 해결하기 위해선 decoder를 더 깊게 만들어야할듯. 이정도 파라미터정도는 되어야 ㅎ --> 메모리가 부족해서 batch_size를 32*8로 줄여야한다. b3을 이용하기..

